Publications
List of publications
2026
- ACL 2026
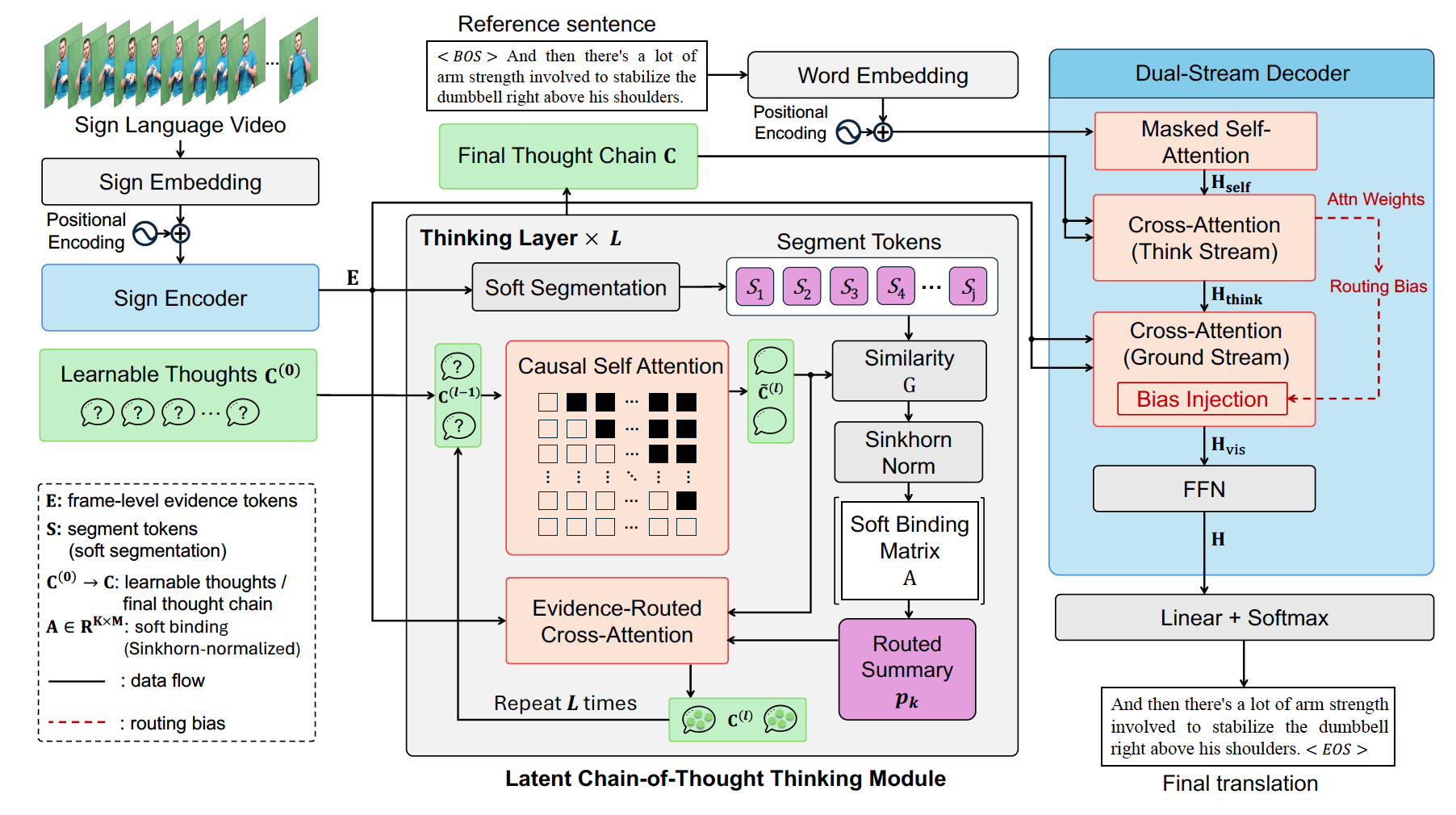 Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language TranslationYiyang Jiang, Li Zhang, Xiao-Yong Wei, and Li QingIn Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics , 2026
Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language TranslationYiyang Jiang, Li Zhang, Xiao-Yong Wei, and Li QingIn Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics , 2026Many SLT systems quietly assume that brief chunks of signing map directly to spoken-language words. That assumption breaks down because signers often create meaning on the fly using context, space, and movement. We revisit SLT and argue that it is mainly a cross-modal reasoning task, not just a straightforward video-to-text conversion. We thus introduce a reasoning-driven SLT framework that uses an ordered sequence of latent thoughts as an explicit middle layer between the video and the generated text. These latent thoughts gradually extract and organize meaning over time. On top of this, we use a plan-then-ground decoding method: the model first decides what it wants to say, and then looks back at the video to find the evidence. This separation improves coherence and faithfulness. We also built and released a new large-scale gloss-free SLT dataset with stronger context dependencies and more realistic meanings. Experiments across several benchmarks show consistent gains over existing gloss-free methods.
@inproceedings{jiang2026thinklatentthoughtsnew, title = {Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language Translation}, author = {Jiang, Yiyang and Zhang, Li and Wei, Xiao-Yong and Qing, Li}, year = {2026}, url = {https://arxiv.org/abs/2604.15301}, booktitle = {Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics}, }

2025
- TMI 2025
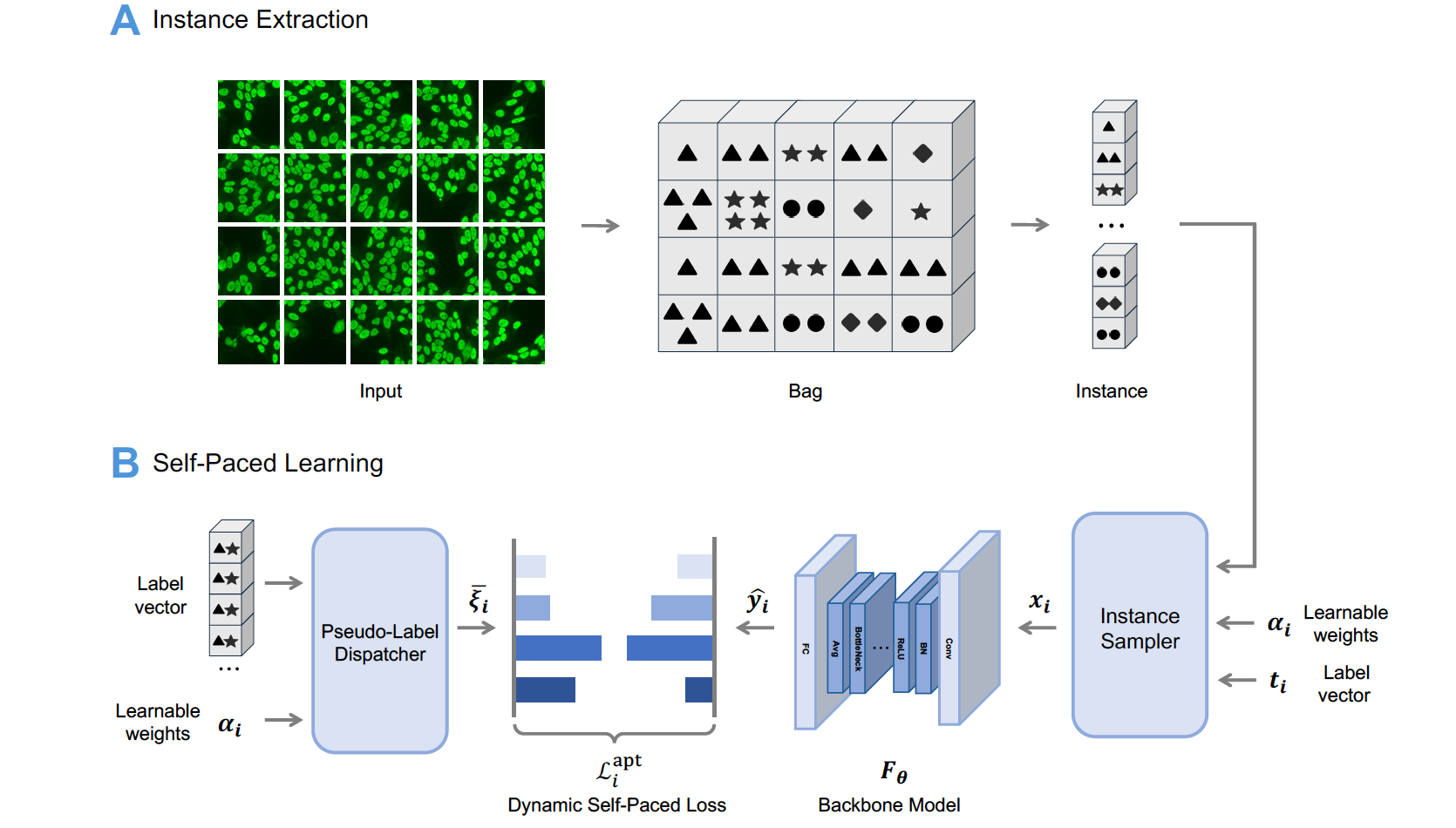 Self-Paced Learning for Images of Antinuclear AntibodiesYiyang Jiang, Guangwu Qian, Jiaxin Wu, Qi Huang, Qing Li, Yongkang Wu, and Xiao-Yong WeiIEEE Transactions on Medical Imaging, 2025
Self-Paced Learning for Images of Antinuclear AntibodiesYiyang Jiang, Guangwu Qian, Jiaxin Wu, Qi Huang, Qing Li, Yongkang Wu, and Xiao-Yong WeiIEEE Transactions on Medical Imaging, 2025Antinuclear antibody (ANA) testing is a critical method for diagnosing autoimmune disorders such as Lupus, Sjögren’s syndrome, and scleroderma. Despite its importance, manual ANA detection is slow, labor-intensive, and demands years of training. ANA detection is complicated by over 100 coexisting antibody types, resulting in vast fluorescent pattern combinations. Although machine learning and deep learning have enabled automation, ANA detection in real-world clinical settings presents unique challenges as it involves multi-instance, multi-label (MIML) learning. In this paper, a novel framework for ANA detection is proposed that handles the complexities of MIML tasks using unaltered microscope images without manual preprocessing. Inspired by human labeling logic, it identifies consistent ANA sub-regions and assigns aggregated labels accordingly. These steps are implemented using three task-specific components: an instance sampler, a probabilistic pseudo-label dispatcher, and self-paced weight learning rate coefficients. The instance sampler suppresses low-confidence instances by modeling pattern confidence, while the dispatcher adaptively assigns labels based on instance distinguishability. Self-paced learning adjusts training according to empirical label observations. Our framework overcomes limitations of traditional MIML methods and supports end-to-end optimization. Extensive experiments on one ANA dataset and three public medical MIML benchmarks demonstrate the superiority of our framework. On the ANA dataset, our model achieves up to +7.0% F1-Macro and +12.6% mAP gains over the best prior method, setting new state-of-the-art results. It also ranks top-2 across all key metrics on public datasets, reducing Hamming loss and one-error by up to 18.2% and 26.9%, respectively.
@article{jiang2025selfpaced, author = {Jiang, Yiyang and Qian, Guangwu and Wu, Jiaxin and Huang, Qi and Li, Qing and Wu, Yongkang and Wei, Xiao-Yong}, journal = {IEEE Transactions on Medical Imaging}, title = {Self-Paced Learning for Images of Antinuclear Antibodies}, year = {2025}, volume = {}, number = {}, pages = {1-1}, keywords = {Antinuclear antibodies;multi-instance learning;multi-label learning;self-paced learning}, url = {https://ieeexplore.ieee.org/document/11269887}, doi = {10.1109/TMI.2025.3637237}, } - ACL 2025
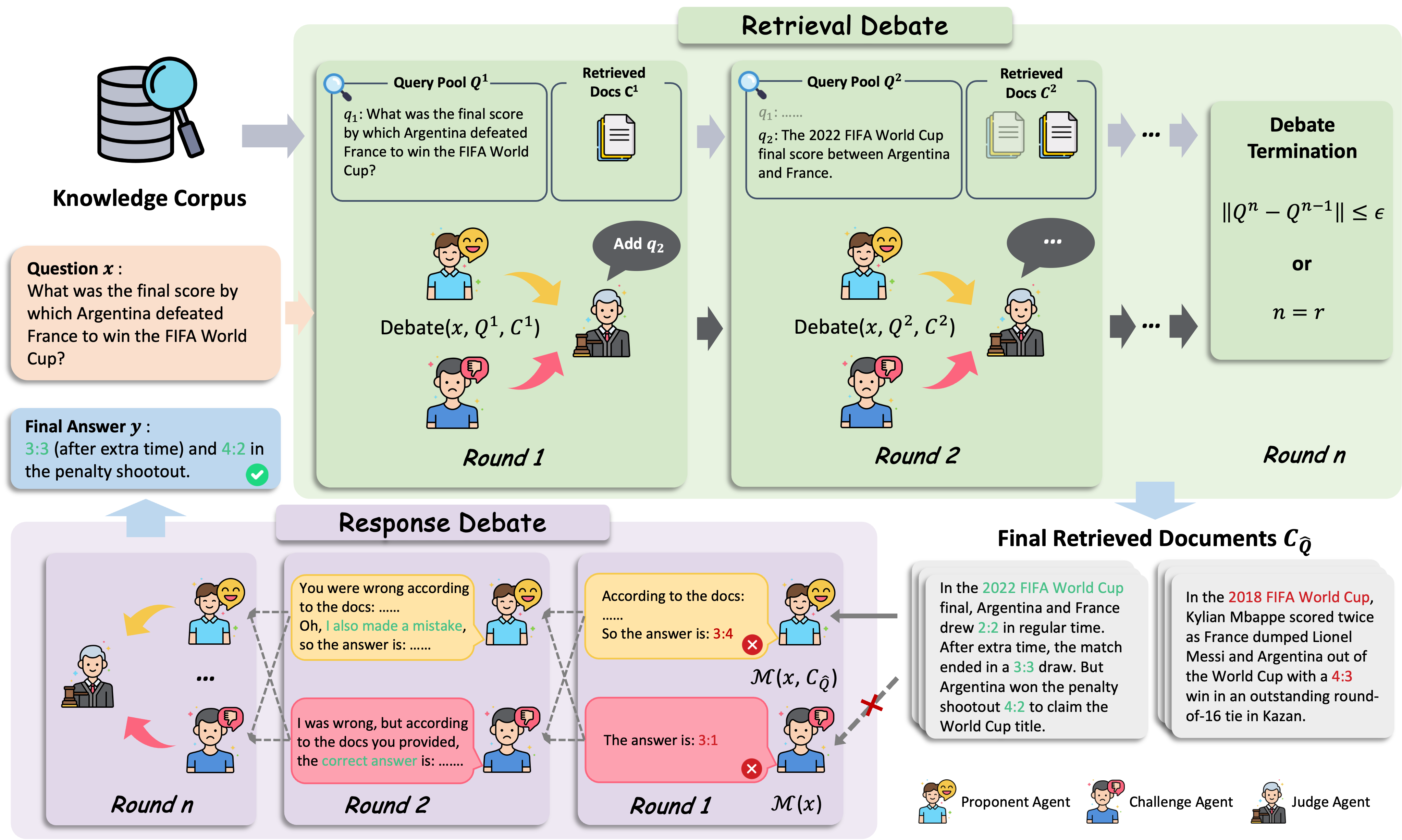 Removal of Hallucination on Hallucination: Debate-Augmented RAGWentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing LiIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , 2025
Removal of Hallucination on Hallucination: Debate-Augmented RAGWentao Hu, Wengyu Zhang, Yiyang Jiang, Chen Jason Zhang, Xiaoyong Wei, and Qing LiIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , 2025Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external knowledge, yet it introduces a critical issue: erroneous or biased retrieval can mislead generation, compounding hallucinations, a phenomenon we term Hallucination on Hallucination. To address this, we propose Debate Augmented RAG (DRAG), a training-free framework that integrates Multi-Agent Debate (MAD) mechanisms into both retrieval and generation stages. In retrieval, DRAG employs structured debates among proponents, opponents, and judges to refine retrieval quality and ensure factual reliability. In generation, DRAG introduces asymmetric information roles and adversarial debates, enhancing reasoning robustness and mitigating factual inconsistencies. Evaluations across multiple tasks demonstrate that DRAG improves retrieval reliability, reduces RAG-induced hallucinations, and significantly enhances overall factual accuracy. Our code is available at https://github.com/Huenao/Debate-Augmented-RAG.
@inproceedings{hu2025removal, title = {Removal of Hallucination on Hallucination: Debate-Augmented RAG}, year = {2025}, author = {Hu, Wentao and Zhang, Wengyu and Jiang, Yiyang and Zhang, Chen Jason and Wei, Xiaoyong and Li, Qing}, booktitle = {Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics}, url = {https://arxiv.org/pdf/2505.18581}, doi = {10.1145/3664647.3681115}, }


2024
- MM 2024
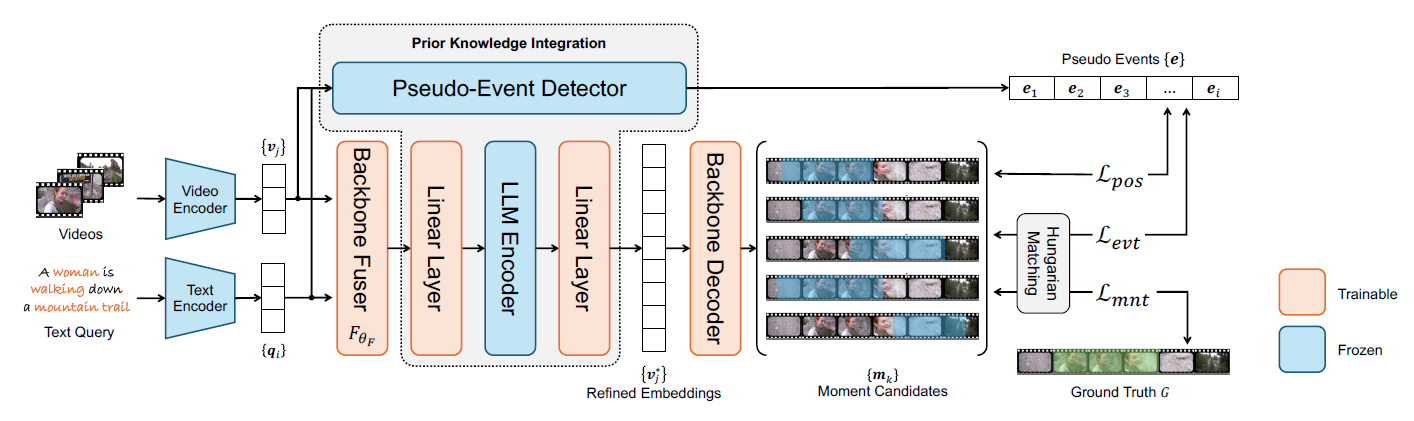 Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn Proceedings of the 32nd ACM International Conference on Multimedia , 2024
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment RetrievalYiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiaoyong Wei, Chang Wen Chen, and Qing LiIn Proceedings of the 32nd ACM International Conference on Multimedia , 2024In this paper, we investigate the feasibility of leveraging large language models (LLMs) for integrating general knowledge and incorporating pseudo-events as priors for temporal content distribution in video moment retrieval (VMR) models. The motivation behind this study arises from the limitations of using LLMs as decoders for generating discrete textual descriptions, which hinders their direct application to continuous outputs like salience scores and inter-frame embeddings that capture inter-frame relations. To overcome these limitations, we propose utilizing LLM encoders instead of decoders. Through a feasibility study, we demonstrate that LLM encoders effectively refine inter-concept relations in multimodal embeddings, even without being trained on textual embeddings. We also show that the refinement capability of LLM encoders can be transferred to other embeddings, such as BLIP and T5, as long as these embeddings exhibit similar inter-concept similarity patterns to CLIP embeddings. We present a general framework for integrating LLM encoders into existing VMR architectures, specifically within the fusion module. The LLM encoder’s ability to refine concept relation can help the model to achieve a balanced understanding of the foreground concepts (e.g., persons, faces) and background concepts (e.g., street, mountains) rather focusing only on the visually dominant foreground concepts. Additionally, we introduce the concept of pseudo-events, obtained through event detection techniques, to guide the prediction of moments within event boundaries instead of crossing them, which can effectively avoid the distractions from adjacent moments. The integration of semantic refinement using LLM encoders and pseudo-event regulation is designed as plug-in components that can be incorporated into existing VMR methods within the general framework. Through experimental validation, we demonstrate the effectiveness of our proposed methods by achieving state-of-the-art performance in VMR.
@inproceedings{jiang2024prior, title = {Prior Knowledge Integration via {LLM} Encoding and Pseudo Event Regulation for Video Moment Retrieval}, year = {2024}, author = {Jiang, Yiyang and Zhang, Wengyu and Zhang, Xulu and Wei, Xiaoyong and Chen, Chang Wen and Li, Qing}, booktitle = {Proceedings of the 32nd ACM International Conference on Multimedia}, pages = {7249–7258}, numpages = {10}, isbn = {9798400706868}, publisher = {Association for Computing Machinery}, url = {https://doi.org/10.1145/3664647.3681115}, doi = {10.1145/3664647.3681115}, }
